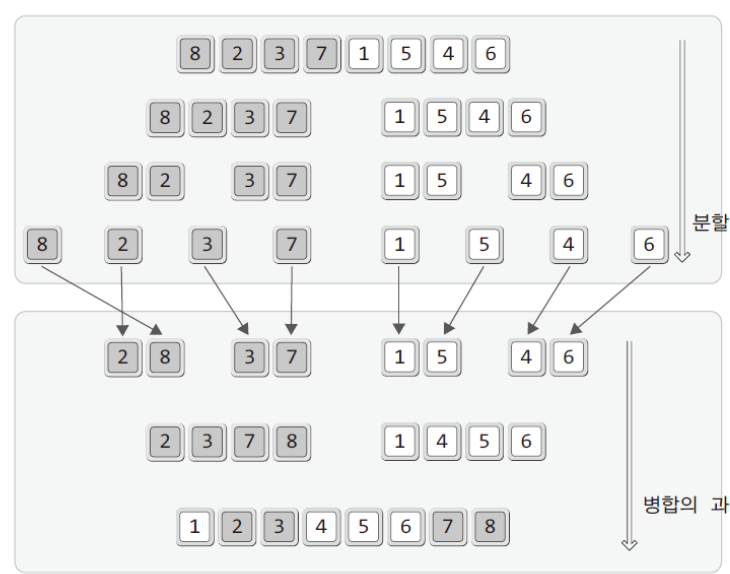
voidMergeSort(int arr[], int left, int right)
{
int mid;
if(left < right) // left가 더 작음 : 더 나눌 수 있음
{
// 중간지점 계산
mid = (left+right)/2;
// 둘로 나눠서 각각 정렬
MergeSort(arr, left, mid); // left ~ mid 정렬
MergeSort(arr, mid+1, right) // mid+1 ~ right 정렬
// 정렬된 두 배열 병합
MergeTwoArray(arr, left, mid, right);
}
}
voidMergeTwoArray(int arr[], int left, int mid, int right)
{
int fIdx = left; int rIdx = mid+1; int i;
int* sortArr = (int*)malloc(sizeof(int) * (right+1)); // 병합 결과를 담을 메모리 공간 할당
// -> 내부에 데이터를 옮기기 번거로워 임시로 공간 할당
int sIdx = left;
// 병합 할 두 영역의 데이터를 비교하여 sortArr에 담음
while(fIdx <= mid && rIdx <= right)
{
if(arr[fIdx] <= arr[rIdx])
sortArr[sIdx] = arr[fIdx++];
else
sortArr[sIdx] = arr[rIdx++];
sIdx++;
}
// 배열의 앞 부분이 sortArr로 모두 이동되어서
// 배열 뒷부분에 남은 데이터를 모두 sortArr로 이동
if(fIdx > mid)
{
for(i=rIdx; i<=right; i++, sIdx++)
sortArr[sIdx] = arr[i];
}
// 배열의 뒷 부분이 sortArr로 모두 이동되어서
// 배열 앞부분에 남은 데이터를 모두 sortArr로 이동
else
{
for(i=fIdx; i <= mid; i++, sIdx++)
sortArr[sIdx] = arr[i];
}
// 병합 결과를 옮겨 담는다.
for(i=left; i<=right; i++)
arr[i] = sortArr[i];
free(sortArr);
}
성능 평가
데이터 비교 및 이동은 MergeTwoArea 함수 중심으로 진행
비교 연산
"정렬 대상 데이터 수가 n개 일때, 각 병합 단계마다 최대 n번의 비교 연산 진행" → \(n\log_2n\) → \(n\log_2n\)
이동 연산
병합 한번 & 저장된 데이터 옮기는 과정 한번 \(2n\log_2n \rightarrow n\log_2n\)
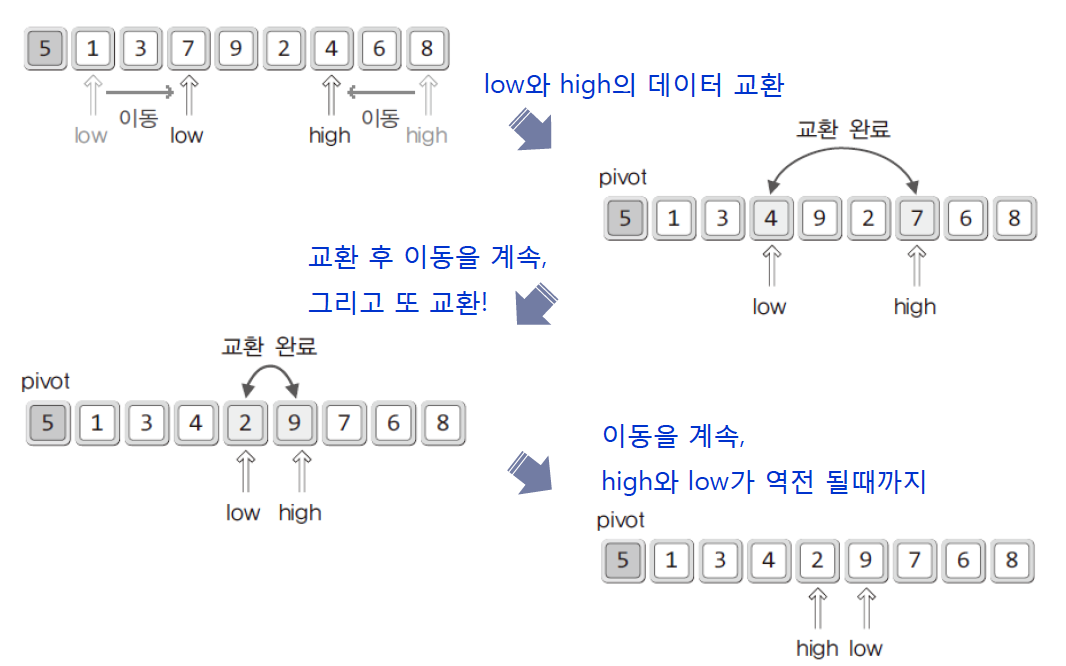
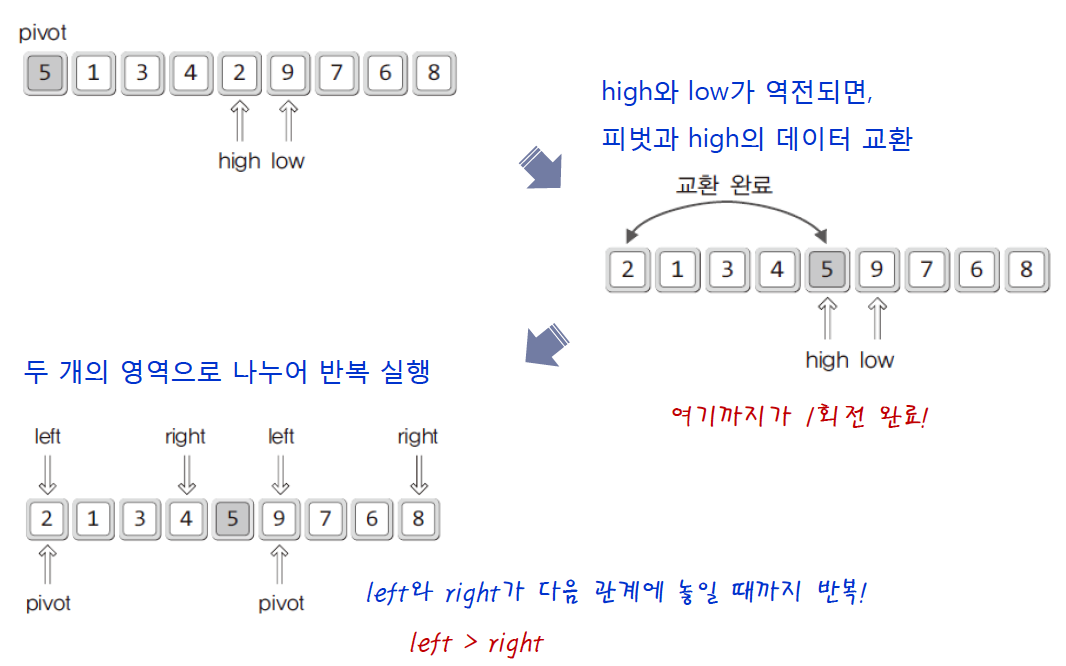
intPartition(int arr[], int left, int right)
{
int pivot = arr[left];
int low = pivot +1;
int high = right;
while(low <= high)
{
// 피벗보다 큰 값을 찾는 과정
while(pivot > arr[low]) // 우선순위 낮은 것 만날때까지
low++;
// 피벗보다 작은 값을 찾는 과정
while(pivot < arr[high]) // 우선순위 높은 것 만날 때까지
high--;
// 교차되지 않는다면 swap
if(low <= high)
Swap(arr, low, high);
}
Swap(arr, left, high); // 피벗과 high의 교환
return high // 옮겨진 피벗의 위치정보 반환
}
재귀적 완성과 수정
1
2
3
4
5
6
7
8
9
voidQuickSort(int arr[], int left, int right)
{
if(left <= right)
{
int pivot = Partition(arr, left, right);
QuickSort(arr, left, pivot-1); // 왼쪽 영역 정렬
QuickSort(arr, pivot+1, right); // 오른쪽 영역 정렬
}
}
arr={3,3,3}의 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
intPartition(int arr[], int left, int right)
{
...
while(low <= high)
{
// while(pivot > arr[low]), 정렬의 범위를 넘지 않도록 경계 검사
while(pivot >= arr[low] && low <= right)
low++;
// while(pivot < arr[high]), 정렬 범위 넘지 않도록 경계 검사
while(pivot <= arr[high] && high >= (left+1))
high--;
}
}
데이터가 불규칙적으로 나열되어 있고 피벗이 중간에 해당하는 값에 가깝게 선택이 될 수록 최상의 경우가 보임 → 불규칙적 나열시 아무거나 선택해도 중간을 선택할 확률이 높다.
중간에 가까운 값으로 빅-오를 선택하려는 노력을 조금만 하더라도 퀵정렬은 최악의 경우를 만들지 않는다. \(\Rightarrow O(n\log_2n)\)
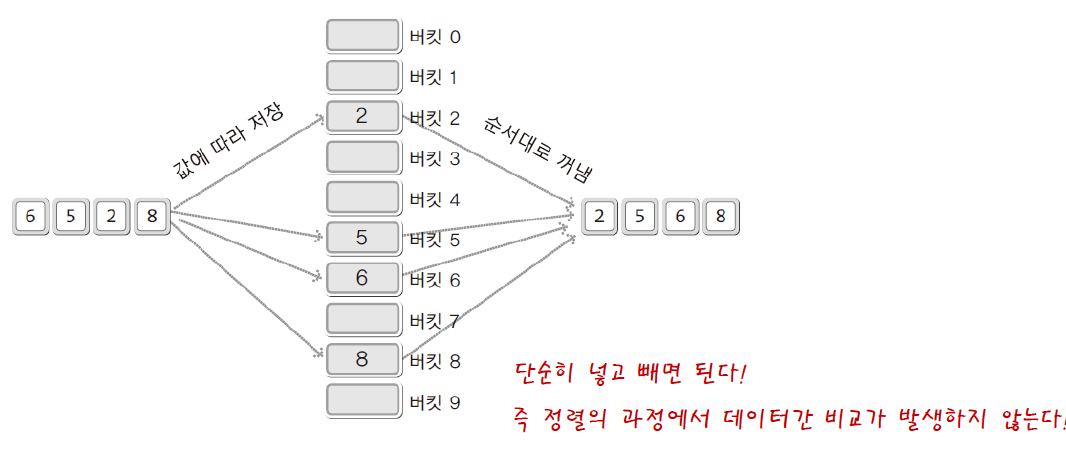
기수 정렬 (Radix Sort)
정렬순서의 앞서고 뒤섬을 비교하지 않는다.
정렬 알고리즘의 한계로 알려진 \(O(n\log_2n)\)을 뛰어 넘을 수 있다.
적용할 수 있는 대상이 매우 제한적이다. 길이가 동일한 데이터들의 정렬에 용이하다!
자리를 찾기 위한 비교연산이 필요할 수 있으나, 버킷을 배열로 만들면 비교 불필요
기수(radix) : 주어진 데이터를 구성하는 기본 요소
버킷(bucket) : 기수의 수에 해당하는 만큼의 버킷 활용
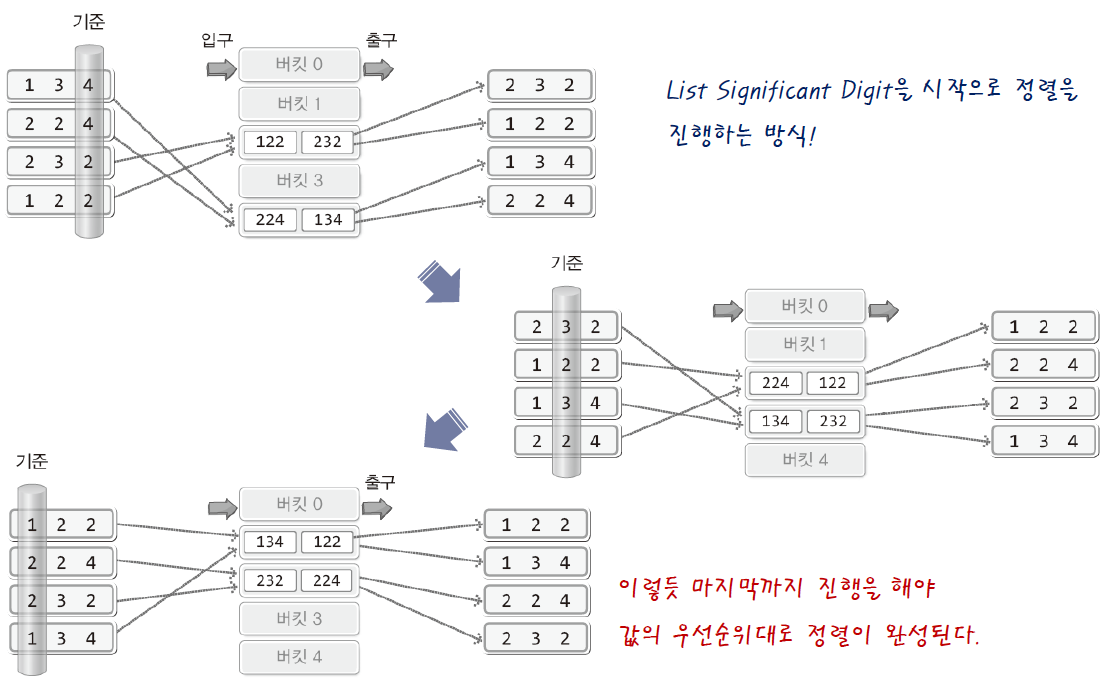
LSD : Least Significant Digit를 시작으로 정렬 진행
LSD 먼저 연산 : "앞 자리가 값이 같다면" 이라는 가정 ⇒ 다음 연산에서 이전 연산 아랫자리 비교 결과 순서는 바꾸지 않는다.
MSD : Most Significant Digit
정렬의 기준 선정 방향 반대
점진적으로 정렬이 완성되어가므로, 중간 중간에 정렬이 완료된 데이터는 더 이상 정렬과정은 진행하지 않아야 함 (선별 과정에서 연산 낭비 증가)