스택은 ‘먼저 들어간 것이 나중에 나오는 자료구조’로써 초코볼이 담겨있는 통에 비유할 수 있다. ⇒ LIFO(Last-in, First-out)
Push : 초코볼 통에 초코볼을 넣는다
Pop : 초코볼 통에서 초코볼을 꺼낸다. (데이터 추출 & 삭제)
Peek : 이번에 꺼낼 초코볼의 색이 무엇인지 통 안을 들여다 본다 (데이터 추출만)
ADT 정의 : 배열 혹은 연결 리스트 기반
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
voidStackInit(Stack * pstack);
// 스택의 초기화 진행, 스택 생성 후 제일 먼저 호출되어야 함
intSIsEmpty(Stack * pstack);
// 스택인 빈 경우 TRUE, 그렇지 않으면 FALSE
voidSPush(Stack * pstack, Data data);
// 스택에 데이터를 저장, 매개변수 data로 전달된 값을 저장
Data SPop(Stack * pstack);
// 마지막에 저장된 요소를 반환하고 삭제
// 본 함수 호출을 위해 데이터가 하나 이상 존재함이 보장되어야 함 => SIsEmpty 사용
Data SPeek(Stack * pstack);
// 마지막 저장요소를 반환하되 삭제하지 않음
// 본 함수 호출을 위해 데이터가 하나 이상 존재함이 보장되어야 함 => SIsEmpty 사용
2. 스택의 배열 기반 구현
구현의 논리
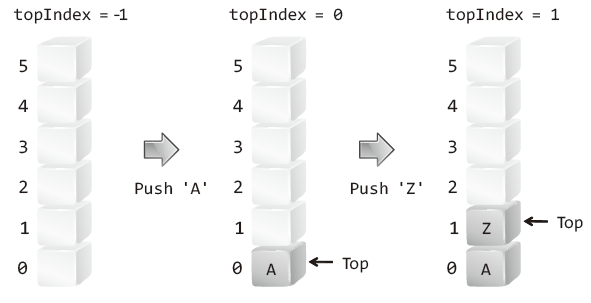
index는 0이 되지 않고 -1이 되어야 참조가 안되어 있음을 확인 가능
인덱스가 0인 위치를 스택의 바닥으로 정의해야 배열 길이에 상관없이 바닥의 인덱스 값이 동일해진다.
// 하나의 함수가 너무 많은 일을 할때 이를 나누는 함수도 큰 의미
// Helper 1
intGetOpPrec(char op) // 연산 우선순위 반환
{
switch(op) // 값이 클 수록 우선순위 높음
{
case'*':case'/':return5;
case'+':case'-':return3;
case'(':// 연산자가 등장 할 때 까지 남아있어야 하므로 가장 낮은 우선순위
return1;
}
// ) 연산자는 소괄호의 끝을 알이므로 쟁반으로 가지 않아서 정의 X
return-1; // 등록되지 않은 연산자
}
// Helper 2
intWhoPrecOp(char op1, char op2) // 두 연산자 우선순위 비교 결과 반환
{
int op1Prec = GetOpPrec(op1);
int op2Prec = GetOpPrec(op2);
if(op1Prec > op2Prec)
return1;
elseif(op1Prec < op2Prec)
return-1;
elsereturn0;
}
voidConvToRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp);
char* convExp = (char*)malloc(expLen+1); // 변환된 수식을 담을 공간 마련
int i, idx=0;
char tok, popOp;
memset(convExp, 0, sizeof(char)*expLen+1); // 공간 0으로 초기화
StackInit(&stack);
for(i=0; i<expLen; i++) // 한 문자씩 처리
{
tok = exp[i];
if(isdigit(tok)) // 피연산자라면 자리잡기
{
convExp[idx++] = tok;
}
else// 연산자라면 stack
{
switch(tok) // stack 순위처리
{
case'(':// 새로운 바닥이므로 무조건 push
SPush(&stack, tok);
break;
case')':// 닫는 소괄호는 과정 진행
while(1)
{
popOp = SPop(&stack); // 스택에서 연산자를 꺼내서
if(popOp =='(') // ( 을 만날 때까지
break;
convExp[idx++] = popOp; // 배열에 저장
}
break;
case'+':case'-':case'*':case'/':// tok에 저장된 연산자를 스택에 저장
while(!SIsEmpty(&stack) && WhoPrecOp(SPeek(&stack), tok) >=0)
convExp[idx++] = SPop(&stack);
SPush(&stack, tok);
break;
}
}
}
while(!SIsEmpty(&stack))
convExp[idx++] = SPop(&stack); // 남은 연산자 모두 이동
strcpy(exp, convExp); // 연환된 수식 반환
free(convExp);
}
intEvalRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp); // 문자의 수
int i;
char tok, op1, op2;
StackInit(&stack);
for(i=0; i<expLen; i++)
{
tok = exp[i];
if(isdigit(tok)) // 피연산자라면
{
SPush(&stack, tok -'0'); // char를 숫자로 변환하여 PUSH!
}
else// 연산자라면
{
op2 = SPop(&stack); // 먼저 꺼낸 값이 두 번째 피연산자!
op1 = SPop(&stack);
switch(tok)
{
case'+':
SPush(&stack, op1+op2);
break;
case'-':
SPush(&stack, op1-op2);
break;
case'*':
SPush(&stack, op1*op2);
break;
case'/':
SPush(&stack, op1/op2);
break;
}
}
} // 최종 결과는 stack에 있음
return SPop(&stack);
}
계산기 프로그램의 완성
중위 표기법 수식 → ConvToRPNExp → EvalRPNExp → 연산 결과
스택의 활용 : ListBaseStack.c
후위 표기법의 수식으로 변환 : InfixToPostfix.c
후위 표기법의 수식을 계산 : PostCalculator.c
중위 표기법의 수식을 계산 (위의 과정 이어 줌) : InfixCalculator.c
InfixCalculatorMain.c
1
2
3
4
5
6
7
8
9
10
11
12
13
intEvalInfixExp(char exp[])
{
int len = strlen(exp);
int ret;
char* expcpy = (char*)malloc(len+1); // 문자열 저장 공간 마련
strcpy(expcpy, exp); // 원본 유지를 위한 복사본 생성
ConvToRPNExp(expcpy); // 후위 표기법으로 수식 변환
ret = EvalRPNExp(expcpy); // 후위 표기법 계산
free(expcpy); // 복사한 저장공간 해제
return ret;
}